The overall aim of our research is to understand how the human brain combines expectations and sensory information to communicate. Our ability to successfully communicate with other people is an essential skill in everyday life. Therefore, unravelling how the human brain is able to derive meaning from acoustic speech signals and to recognize our communication partner based on seeing a face represents an important scientific endeavour.
Speech recognition depends on both the clarity of the acoustic input and on what we expect to hear. For example, in noisy listening conditions, listeners of the identical speech input can differ in their perception of what was said. Similarly for face recognition, brain responses to faces depend on expectations and do not simply reflect the presented facial features.
These findings for speech and face recognition are compatible with the more general view that perception is an active process in which incoming sensory information is interpreted with respect to expectations. The neural mechanisms supporting such integration of sensory signals and expectations, however, remain to be identified. Conflicting theoretical and computational models have been suggested for how, when, and where expectations and new sensory information are combined.
Predictions in speech perception
The pupil dilation response as an indicator of visual cue uncertainty and auditory outcome surprise

Expectations can be induced by cues that indicate the probability of following sensory events. The information provided by cues may differ and hence lead to different levels of uncertainty about which event will follow. In this experiment, we employed pupillometry to investigate whether the pupil dilation response to visual cues varies depending on the level of cue-associated uncertainty about a following auditory outcome.
Read moreBecker, J., Viertler, M., Korn, C., & Blank, H., (2024) The pupil dilation response as an indicator of visual cue uncertainty and auditory outcome surprise. European Journal of Neuroscience, 1-16.
doi.org/10.1111/ejn.16306
Pupil diameter as an indicator of sound pair familiarity after statistically structured auditory sequence

Inspired by recent findings in the visual domain, we investigated whether the stimulus-evoked pupil dilation reflects temporal statistical regularities in sequences of auditory stimuli. Our findings suggest that pupil diameter may serve as an indicator of sound pair familiarity but does not invariably respond to task-irrelevant transition probabilities of auditory sequences.
Read moreBecker, J., Korn, C.W. & Blank, H. (2024) Pupil diameter as an indicator of sound pair familiarity after statistically structured auditory sequence. Scientific Reports, 14, 8739.
doi.org/10.1038/s41598-024-59302-1
Multivariate analysis to unravel predictive processes in speech
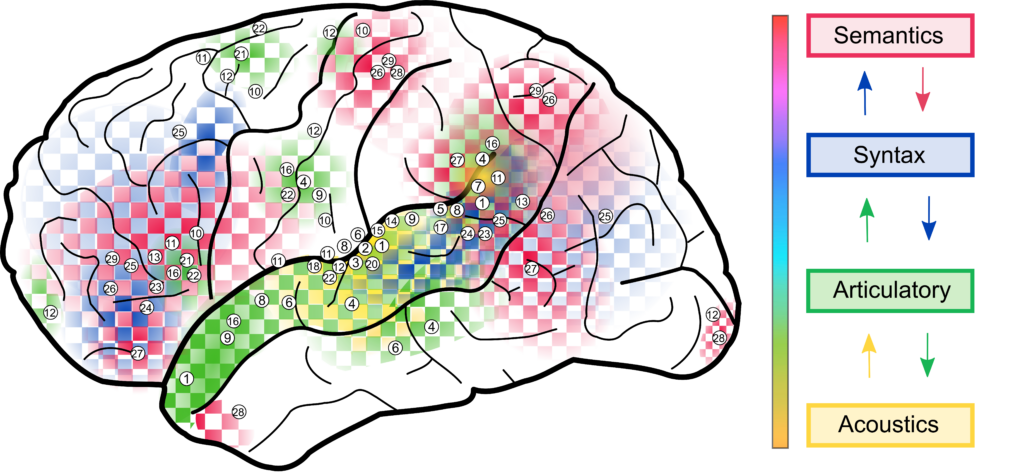
Speech perception is heavily influenced by our expectations about what will be said. In this review, we discuss the potential of multivariate analysis as a tool to understand the neural mechanisms underlying predictive processes in speech perception.
Read moreUfer, C. & Blank, H., (2023). Multivariate analysis of brain activity patterns as a tool to understand predictive processes in speech perception. Language, Cognition and Neuroscience.
doi.org/10.1080/23273798.2023.2166679
Speech perception depends on speaker priors
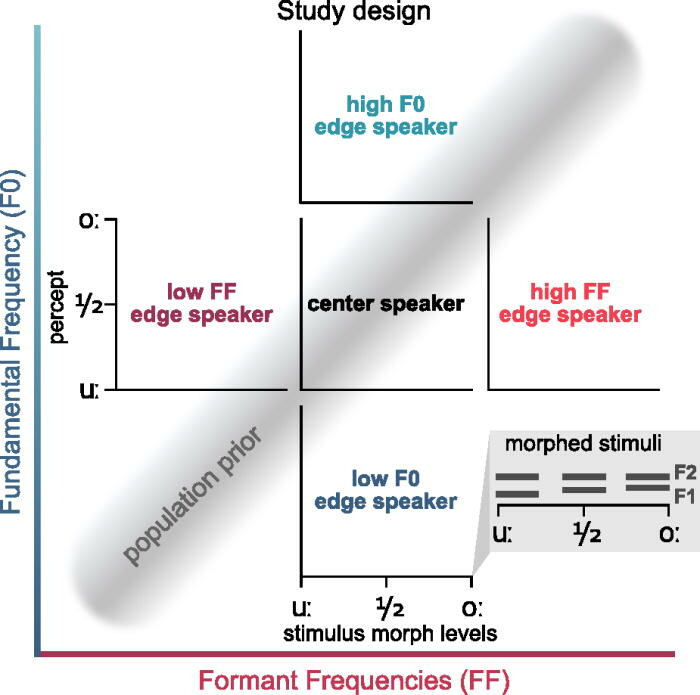
When different speakers articulate identical words, the physical properties of the produced sounds can vary substantially. Fundamental frequency (F0) and formant frequencies (FF), the two main parameters that discriminate between voices, also influence vowel perception. In this study we investiagted how we use speaker prior information when decoding the speech stream.
Read moreKrumbiegel J, Ufer C, Blank H (2022) Influence of voice properties on vowel perception depends on speaker context. The Journal of the Acoustical Society of America 152:820–834. doi.org/10.1121/10.0013363
Prediction errors during speech perception
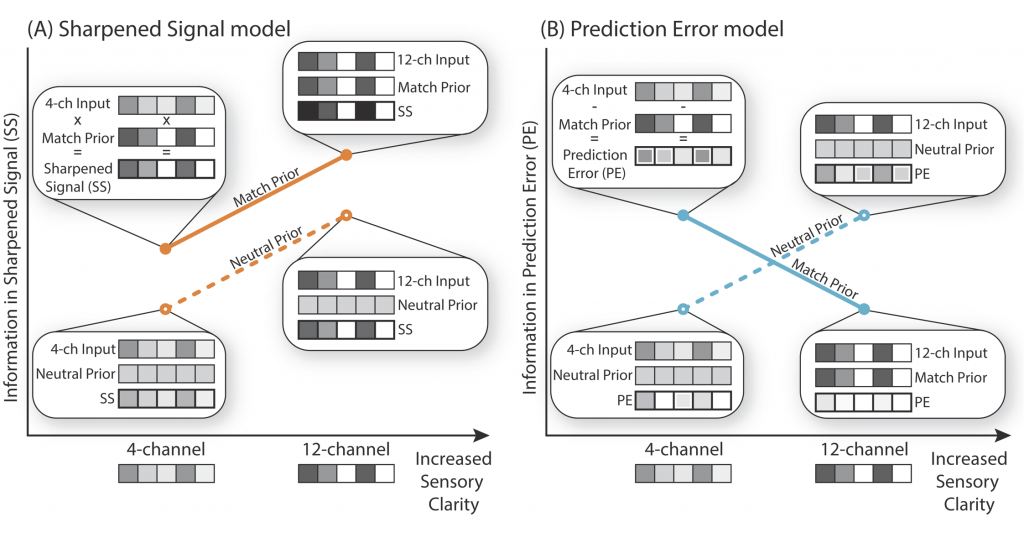
Perception inevitably depends on combining sensory input with prior expectations, particularly for identification of degraded input. However, the underlying neural mechanism by which expectations influence sensory processing is unclear. Predictive Coding suggest that the brain passes forward the unexpected part of the sensory input while expected properties are suppressed (Prediction Error). However, evidence to rule out the opposite and perhaps more intuitive mechanism, in which the expected part of the sensory input is enhanced (Sharpening), has been lacking.
Read moreBlank, H. & Davis, M. (2016). Prediction errors but not sharpened signals simulate multivoxel fMRI patterns during speech perception, PLOSBiology, 14(11) doi.org/10.1371/journal.pbio.1002577
Slips of the Ear: When Knowledge Deceives Perception
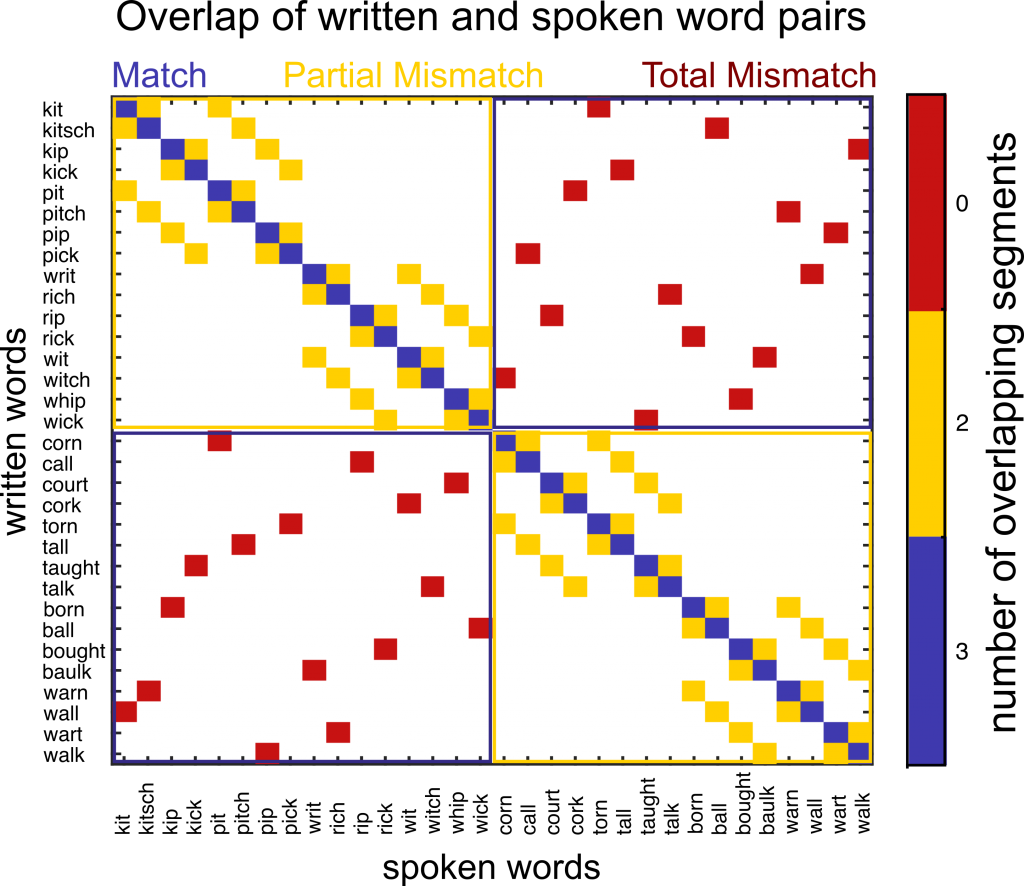
The ability to draw on past experience is important to keep up with a conversation, especially in noisy environments where speech sounds are hard to hear. However, these prior expectations can sometimes mislead listeners; convincing them that they heard something that a speaker did not actually say.
Read moreUsing fMRI, we found that misperception was associated with reduced activity in the left superior temporal sulcus a brain region critical for processing speech sounds. Furthermore, when perception of speech was more successful, this brain region represented the difference between prior expectations and heard speech (like the initial k/p in kick-pick).
Blank, H., Spangenberg, M., & Davis, M. (2018). Neural Prediction Errors Distinguish Perception and Misperception of Speech. The Journal of Neuroscience, . 38 (27) 6076-6089.
https://doi.org/10.1523/JNEUROSCI.3258-17.2018
Predictions in face perception
Prediction error processing and sharpening of expected information across the face-processing hierarchy

The perception and neural processing of sensory information are strongly influenced by prior expectations. The integration of prior and sensory information can manifest through distinct underlying mechanisms: focusing on unexpected input, denoted as prediction error (PE) processing, or amplifying anticipated information via sharpened representation. In this study, we employed computational modeling using deep neural networks combined with representational similarity analyses of fMRI data to investigate these two processes during face perception.
Read moreGarlichs, A., Blank, H. (2024). Prediction error processing and sharpening of expected information across the face-processing hierarchy. Nature Communications, 15, 3407. doi.org/10.1038/s41467-024-47749-9
Representations of face priors
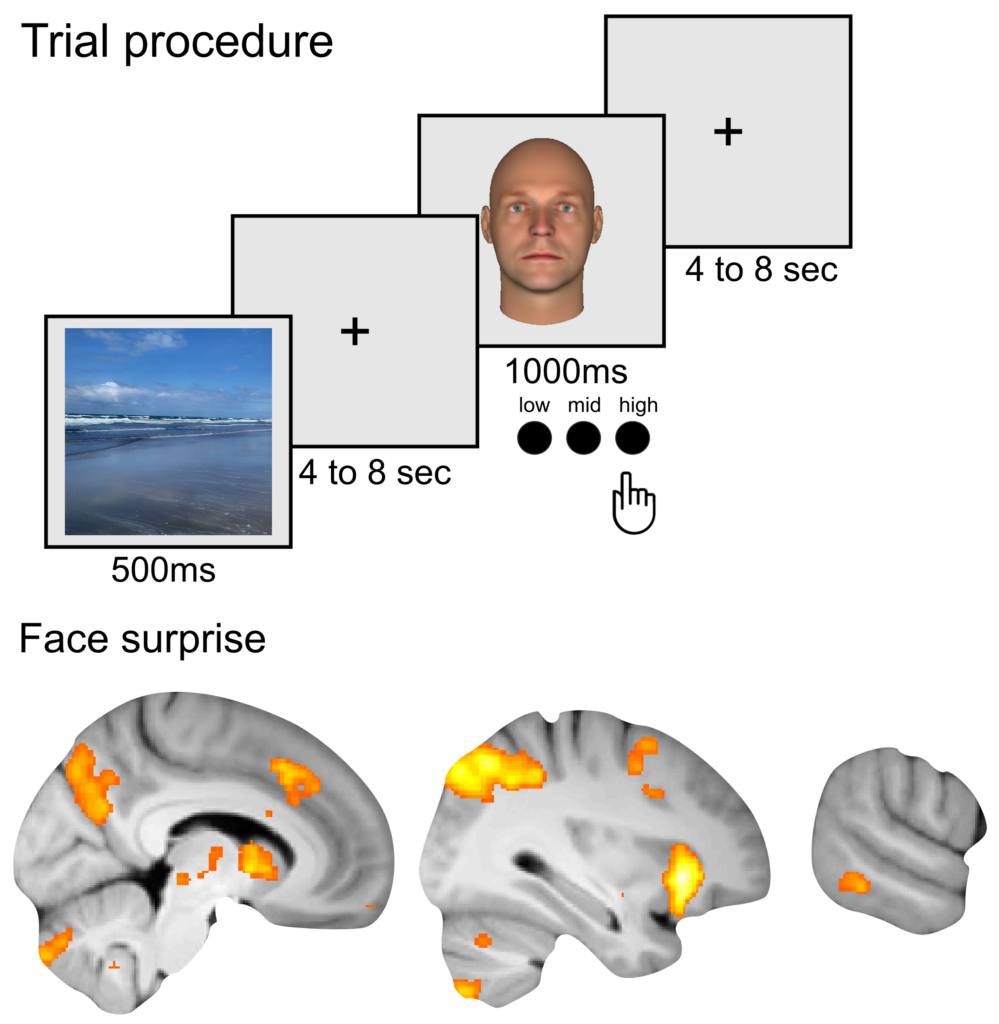
In everyday life, we face our environment with several prior expectations about what we are going to encounter, for example, whom we are going to see most likely at a certain location. These expectations have to be weighted according to their probability, e.g., a student regularly entering our office will be expected with a higher probability than a shy colleague we rarely meet. In this study, we show that the human brain weights face priors according to their certainty in high-level face-sensitive regions.
Read moreBlank, H., Alink, A., & Büchel, C. (2023). Multivariate functional neuroimaging analyses reveal that strength-dependent face expectations are represented in higher-level face-identity areas. Communications Biology, 6, 135. doi.org/10.1038/s42003-023-04508-8
Direct structural connections between face and voice ares
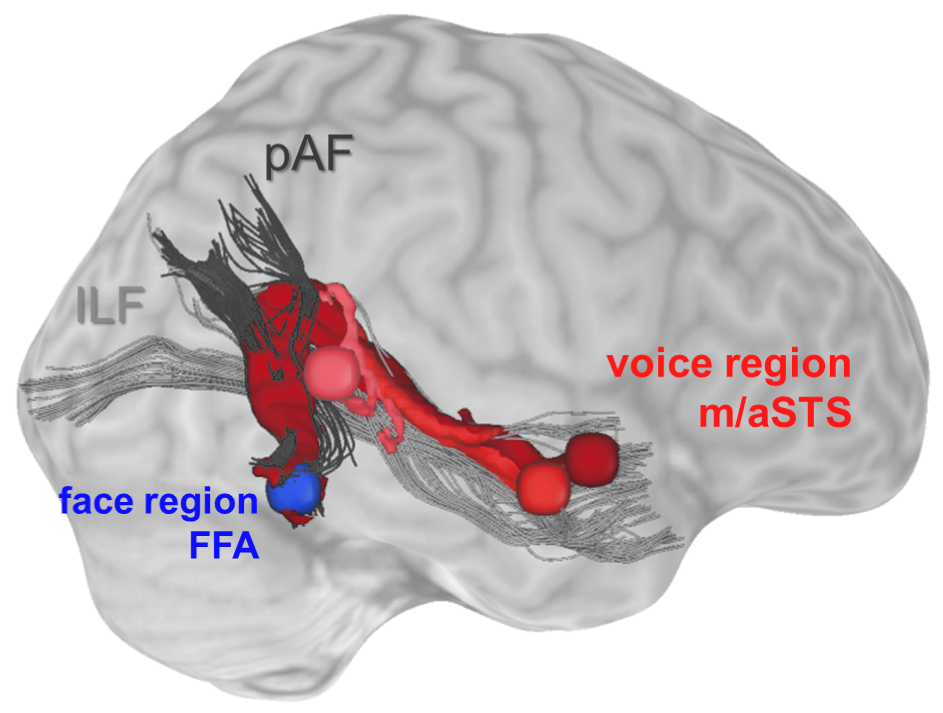
By combining fMRI with diffusion-weighted imaging we could show that the brain is equipped with direct structural connections between face- and voice-recognition areas to activate learned associations of faces and voices even in unimodal conditions to improve person-identity recognition.
Read moreWhat kind of information is exchanged between these specialized areas during cross‐modal recognition of other individuals? To address this question, we used functional magnetic resonance imaging and a voice‐face priming design. In this design, familiar voices were followed by morphed faces that matched or mismatched with respect to identity or physical properties. The results showed that responses in face‐sensitive regions were modulated when face identity or physical properties did not match to the preceding voice. The strength of this mismatch signal depended on the level of certainty the participant had about the voice identity. This suggests that both identity and physical property information was provided by the voice to face areas.
Blank, H., Anwander, A., & von Kriegstein, K. (2011). Direct structural connections between voice- and face-recognition areas. The Journal of Neuroscience, 31(36), 12906-12915. https://doi.org/10.1523/JNEUROSCI.2091-11.2011
Blank, H., Kiebel, S. J. & von Kriegstein, K. (2015). How the human brain exchanges information across sensory modalities to recognize other people. Human Brain Mapping, 36(1), 324-39. http://dx.doi.org/10.1002/hbm.22631
Lipreading: How we “hear” with our eyes
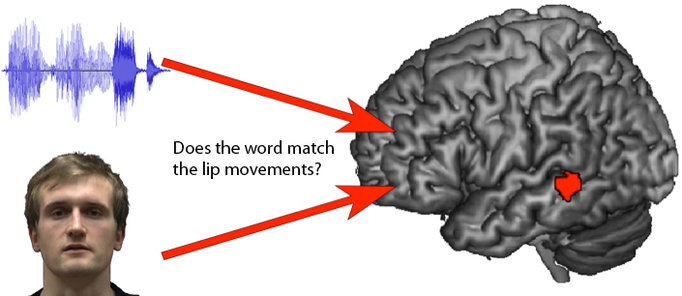
In a noisy environment it is often very helpful to see the mouth of the person you are speaking to. When our brain is able to combine information from different sensory sources, for example during lip-reading, speech comprehension is improved.
Read moreBlank, H. & von Kriegstein, K. (2013). Mechanisms of enhancing visual-speech recognition by prior auditory information. Neuroimage, 65, 109-118. http://dx.doi.org/10.1016/j.neuroimage.2012.09.047